In this tutorial, we are going to learn about a project ChatwithDocs which let’s you interact with your Documents in just few steps.
Large Langauge Models (LLM) have started a whole new revolution in Artificial Industry. There are loads of new applications being developed on LLMs on a daily basis. The only grey area that these LLMs had was the amount of text that they could handle at once. Meaning we cannot use our docs and ask questions on the docs directly in these LLMs.
This grey area has been smartly handled by Langchain and Llama-Index. Not only we can input our long format document, we can now interact with LLM as well.
ChatwithDocs is a python based project designed using Llama-Index and Streamlit. You can interact with CSV/PDFs/TxT/Docs format documents in 2-3 steps.
Prerequisites
You only need the following things to get started with this project.
- OpenAI API Key: You will have to create an account on OpenAI and then get key from here.
- Working Python Programming knowledge, which can be started from here
Coding Section
To use the project we need to do the following things:
- Clone or download the project from GITHUB: Chat with Docs
- Install the required python libraries.
- Run the project
Once you are done with cloning and installing the required packages. We need to make one folder in the same directory where the .py is present and name it as documents. For the UI perspective, we are using Streamlit, Which helps to develop UI in python programming language.
Assuming all the above steps are done at your end, Let’s look at the code. The code contains different sections.
- Two tabs, One to handle CSV and other to other format documents.
- Storing documents inside a folder until vectors are created and then removing them
- Interacting with CSV file using PandasAI loader, Which is a wrapper over PandasAI library
- Cache the Vectors so that we do not end up creating embeddings again and again.
- Query the docs and generate response.
Interact with CSV
PandasAIReader = download_loader("PandasAIReader")
def get_csv_result(df, query):
reader = PandasAIReader(llm=csv_llm)
response = reader.run_pandas_ai(
df,
query,
is_conversational_answer=False
)
return response
Code language: Python (python)We Initialized a CSV reader using PandasAIReader which is a wrapper over PandasAI project. It helps to interact with our CSV file using the power of LLM. This makes it easier to find insights on the data. Rather than going to and fro on the data you can simply ask!.
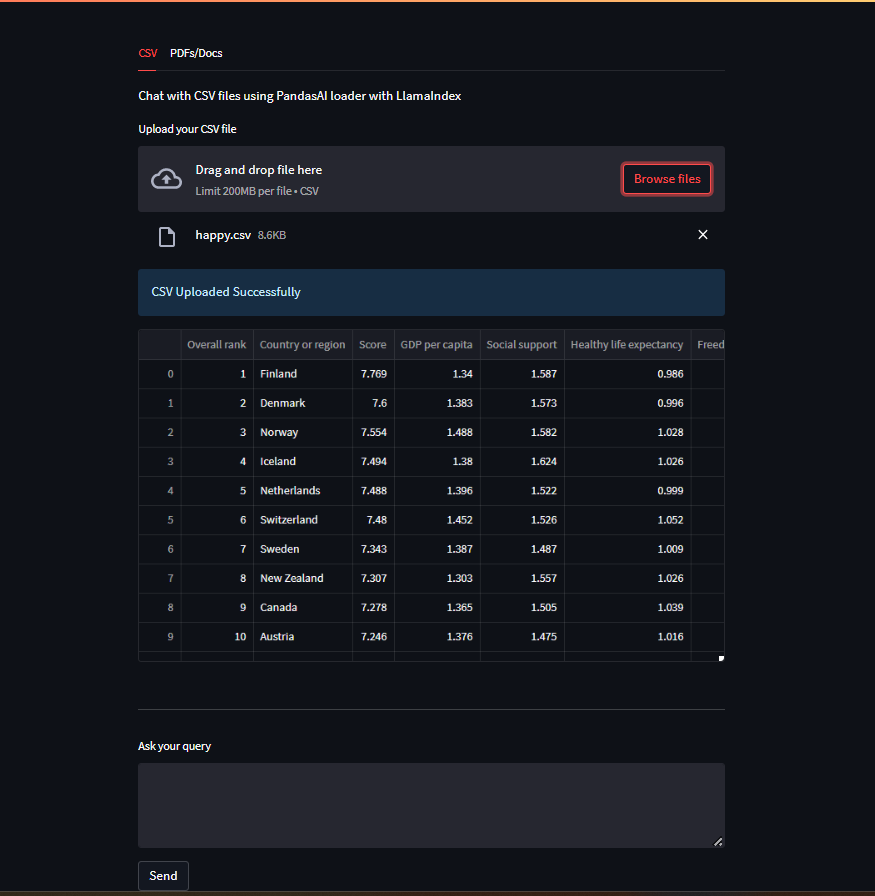
Ask questions, based on your dataset and you will get your answers
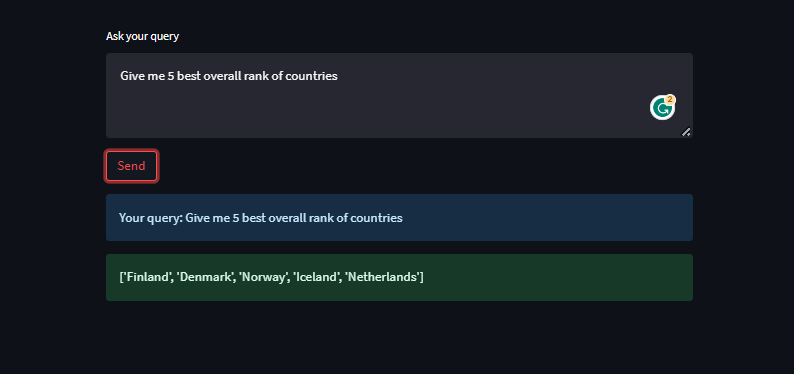
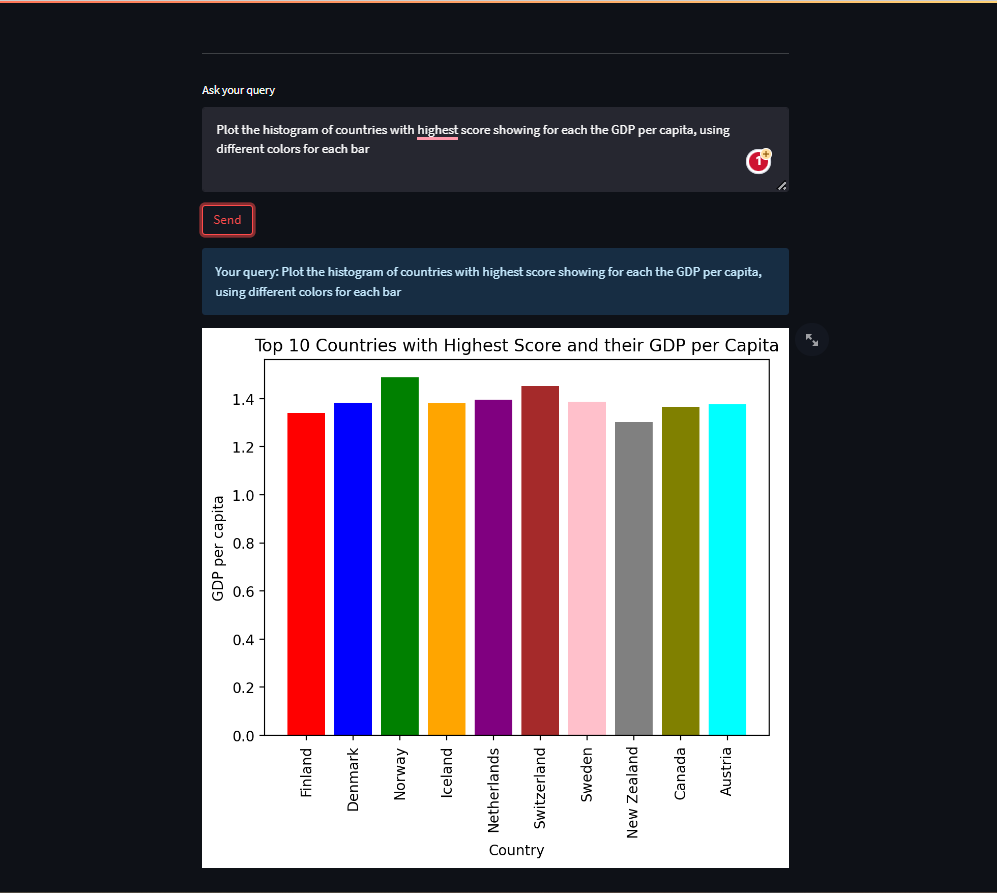
Renders graphs as well
Interact with Docs
This section let’s you interact with other form of documents such as PDFs/TxT/Docs.
def save_file(doc):
fn = os.path.basename(doc.name)
# open read and write the file into the server
open(documents_folder+'/'+fn, 'wb').write(doc.read())
# Check for the current filename, If new filename
# clear the previous cached vectors and update the filename
# with current name
if st.session_state.get('file_name'):
if st.session_state.file_name != fn:
st.cache_resource.clear()
st.session_state['file_name'] = fn
else:
st.session_state['file_name'] = fn
return fn
def remove_file(file_path):
# Remove the file from the Document folder once
# vectors are created
if os.path.isfile(documents_folder+'/'+file_path):
os.remove(documents_folder+'/'+file_path)
@st.cache_resource
def create_index():
# Create vectors for the file stored under Document folder.
# NOTE: You can create vectors for multiple files at once.
documents = SimpleDirectoryReader(documents_folder).load_data()
index = GPTVectorStoreIndex.from_documents(documents)
return index
def query_doc(vector_index, query):
# Applies Similarity Algo, Finds the nearest match and
# take the match and user query to OpenAI for rich response
query_engine = vector_index.as_query_engine()
response = query_engine.query(query)
return response
Code language: Python (python)These are the four main methods which are helping us from uploading a doc to query on a doc steps.
save_filehelps us to save the file in the required folder which is used to generate embeddingsremove_filemethod removes the file from the folder once the embeddings are generatedcreate_indexmethod interacts with LLM ( default with OpenAI) and generate embeddings which are used in the query part.query_docmethod takes user query and the embeddings of the document and finds the nearest possible section using Cosine similarity or any other Nearest neighbors algorithm. Once found, it sends the only required part to LLM to generate rich response.
Once the doc is uploaded, You can start asking your queries related to doc.
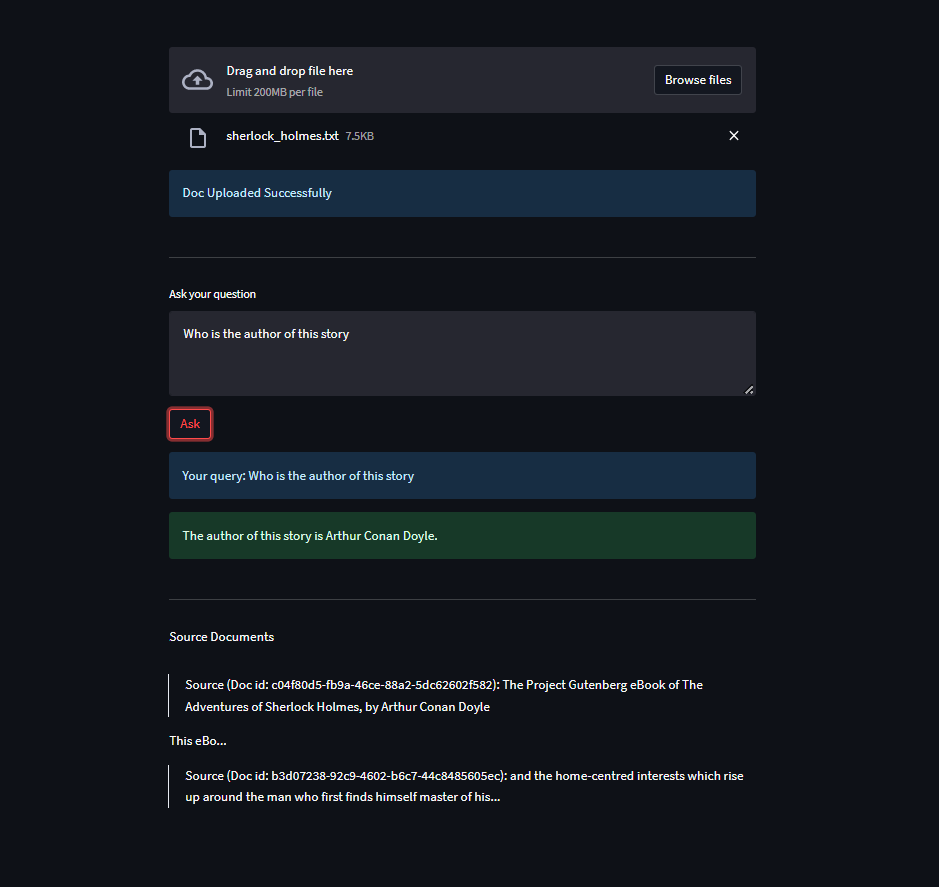
To begin with, Sample documents have been added in Sample Docs folder in the Github repo. You can use those documents and start asking questions.
You can find the code on 🖥️ GitHub | Feel free to give ⭐


