
What is LlamaIndex🦙?
LlamaIndex is a data framework which helps to interact with your custom knowledge such as your local documents using Large Language model (LLM). It has gain immense popularity among developers as it only takes 4-5 lines of code to query your local documents.
If you’re new to the world of LLamaIndex, we highly recommend familiarizing yourself with the LlamaIndex Boilerplate. This resource offers invaluable insights into the fundamental concepts of LlamaIndex, enabling you to grasp its potential and functionalities more effectively.
Llama Debug Handler
In this article, we are going to learn how we can debug our queries in LlamaIndex more efficiently. Each query goes through different stages in LlamaIndex before we get the final response. And it would be better if we have the idea about each of these steps like how much time each of the sub process is taking.
Not only the query part, Data ingestion also goes through different stages in LlamaIndex before we can actually query over them. The main benefits that we can have with debugging are:
- Easily verify how much time each sub process is taking.
- Identify which process takes more/less time during query operation.
- Check what values these sub processes contain during each operation like Data Ingestion and Query operation.
Well to do all of this we do not have to use any library or tool. LlamaIndex itself provides a way to Debug better with the help of a feature called Llama Debug Handler.
Let’s checkout how we can use this in code to understand its capabilities better. I have written down a basic boiler plate code to load a file and create embeddings below.
from llama_index import (
ServiceContext, VectorStoreIndex,
SimpleDirectoryReader
)
from llama_index.llms import OpenAI
from llama_index.callbacks import CallbackManager, LlamaDebugHandler, CBEventType
llm = OpenAI(model="gpt-3.5-turbo", temperature=0)
llama_debug = LlamaDebugHandler(print_trace_on_end=True)
# creating Callback manager object to show each sub process details \
callback_manager = CallbackManager([llama_debug])
# Service context contains information about which LLM we
# are going to use for response generation and which
# embedding model to create embeddings. Default is
# GPT-3 Davinci and OpenAI embeddings model ADA
service_context = ServiceContext.from_defaults(
callback_manager=callback_manager, llm=llm
)
# Creates node objects of the given file
docs = SimpleDirectoryReader(input_files=['PATH_TO_A_FILE_LOCATION']).load_data()
# This is where out docs gets converted into Embeddings
index = VectorStoreIndex.from_documents(docs, service_context=service_context)
# Creating a query engine instance with the current index object
query_engine = index.as_query_engine()
Code language: Python (python)In the above code we have added our callback manager in the service context which will help us to show the information regarding each sub-process for document ingestion part.
Let’s try running this code. You’ll see something like this in your terminal:
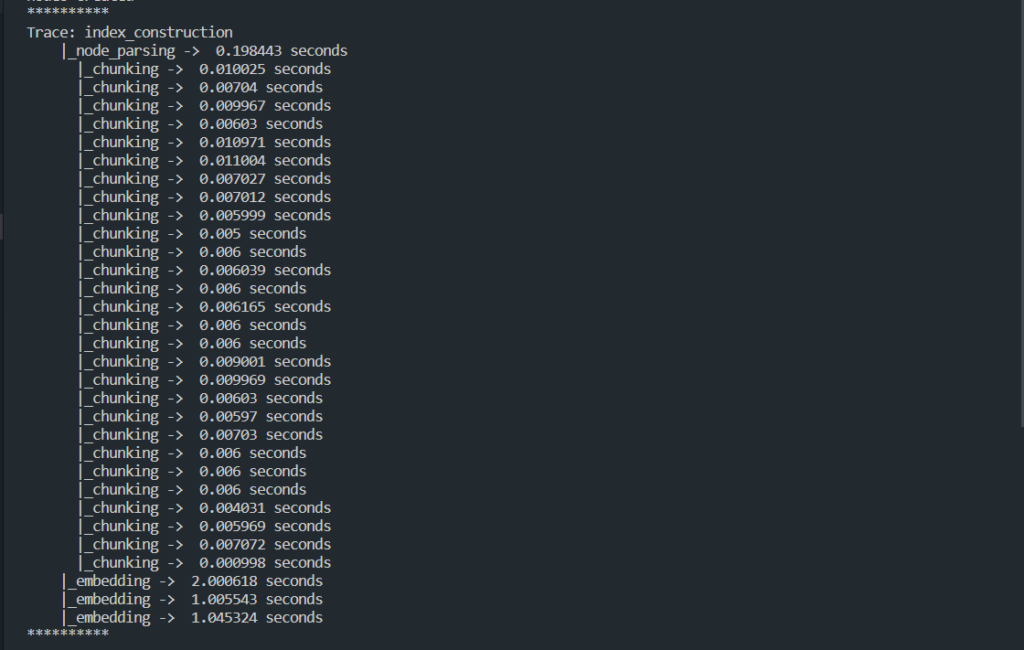
As you can see the document that I provided got divided into multiple chunks of default size ( 1024 tokens ). It also shows how much time it takes for each chunking. Once the breaking of document into smaller chunks is done. It is then converted into embeddings ( Vectors ) and you can see in the logs that as well.
Let’s check out the logs to debug what happen when we query our document using LlamaIndex. To do that add this piece of code in the above code and run the code again.
response = query_engine.query("What did the author do growing up?")
Code language: Python (python)After running this piece of code you’ll see what happens when you query your own data.

- It will first convert your query into embedding.
- Applies cosine similarity algorithm to find nearest embeddings from the document chunks created in the above step.
- Once found, Combine the nearest embedding related text and user query and pass it to the LLM in our case it’s OpenAI.
- OpenAI generates the response based on context and user query and send it back as the response.
Isn’t this great! Every part of the process is shows as logs for you to debug if there is any issue in your case.
Llama Debug Handler not only show the time for each process. Infact at any time of the process, you can check and debug every process and find out what is going on in here.
For example, If you want to check how many LLM calls you have made until the file is running, You can do that simply like this by adding this line of code at the end of the above code.
# Print info on the LLM calls during the list index query
print(llama_debug.get_event_time_info(CBEventType.LLM))
# Output on the terminal will be like this
EventStats(total_secs=1.509315, average_secs=1.509315, total_count=1)
Code language: Python (python)If you want to check what was sent to LLM and what LLM returned back, You can do that by simply adding this line of code at the bottom.
# Print info on llm inputs/outputs - returns start/end events for each LLM call
event_pairs = llama_debug.get_llm_inputs_outputs()
print(event_pairs[0][0]) # Shows what was sent to LLM
print(event_pairs[0][1].payload.keys()) # What other things you can debug by simply passing the key
print(event_pairs[0][1].payload["response"]) # Shows the LLM response it generated.
# Output will be something like this on your terminal
CBEvent(event_type=<CBEventType.LLM: 'llm'>, payload={'context_str': 'page_label: 1\nfile_name: Paul_Graham_Essay.pdf\n\nWhat I Worked OnFebruary 2021Before college the two main things I worked on, outside of school, were writing and programming. I didn\'t write essays. I wrote what beginning writers were supposed to write then, and probably still are: short stories. My stories were awful. They had hardly any plot, just characters with strong feelings, which I imagined made them deep.The first programs I tried writing were on the IBM 1401 that our school district used for what was then called "data processing." This was in 9th grade, so I was 13 or 14. The school district\'s 1401 happened to be in the basement of our junior high school, and my friend Rich Draves and I got permission to use it. It was like a mini Bond villain\'s lair down there, with all these alien-looking machines — CPU, disk drives, printer, card reader — sitting up on a raised floor under bright fluorescent lights.The language we used was an early version of Fortran. You had to type programs on punch cards, then stack them in the card reader and press a button to load the program into memory and run it. The result would ordinarily be to print something on the spectacularly loud printer.I was puzzled by the 1401. I couldn\'t figure out what to do with it. And in retrospect there\'s not much I could have done with it. The only form of input to programs was data stored on punched cards, and I didn\'t have any data stored on punched cards. The only other option was to do things that didn\'t rely on any input, like calculate approximations of pi, but I didn\'t know enough math to do anything interesting of that type. So I\'m not surprised I can\'t remember any programs I wrote, because they can\'t have done much. My clearest memory is of the moment I learned it was possible for programs not to terminate, when one of mine didn\'t. On a machine without time-sharing, this was a social as well as a technical error, as the data center manager\'s expression made clear.With microcomputers, everything changed. Now you could have a computer sitting right in front of you, on a desk, that could respond to your keystrokes as it was running instead of just churning through a stack of punch cards and then stopping. [1]The first of my friends to get a microcomputer built it himself. It was sold as a kit by Heathkit. I remember vividly how impressed and envious I felt watching him sitting in front of it, typing programs right into the computer.Computers were expensive in those days and it took me years of nagging\n\npage_label: 17\nfile_name: Paul_Graham_Essay.pdf\n\nelse I did, I\'d always write essays too.I knew that online essays would be a marginal medium at first. Socially they\'d seem more like rants posted by nutjobs on their GeoCities sites than the genteel and beautifully typeset compositions published in The New Yorker. But by this point I knew enough to find that encouraging instead of discouraging.One of the most conspicuous patterns I\'ve noticed in my life is how well it has worked, for me at least, to work on things that weren\'t prestigious. Still life has always been the least prestigious form of painting. Viaweb and Y Combinator both seemed lame when we started them. I still get the glassy eye from strangers when they ask what I\'m writing, and I explain that it\'s an essay I\'m going to publish on my web site. Even Lisp, though prestigious intellectually in something like the way Latin is, also seems about as hip.It\'s not that unprestigious types of work are good per se. But when you find yourself drawn to some kind of work despite its current lack of prestige, it\'s a sign both that there\'s something real to be discovered there, and that you have the right kind of motives. Impure motives are a big danger for the ambitious. If anything is going to lead you astray, it will be the desire to impress people. So while working on things that aren\'t prestigious doesn\'t guarantee you\'re on the right track, it at least guarantees you\'re not on the most common type of wrong one.Over the next several years I wrote lots of essays about all kinds of different topics. O\'Reilly reprinted a collection of them as a book, called Hackers & Painters after one of the essays in it. I also worked on spam filters, and did some more painting. I used to have dinners for a group of friends every thursday night, which taught me how to cook for groups. And I bought another building in Cambridge, a former candy factory (and later, twas said, porn studio), to use as an office.One night in October 2003 there was a big party at my house. It was a clever idea of my friend Maria Daniels, who was one of the thursday diners. Three separate hosts would all invite their friends to one party. So for every guest, two thirds of the other guests would be people they didn\'t know but would probably like. One of the guests was someone I didn\'t know but would turn out to like a lot: a woman called Jessica Livingston. A couple days later I asked her out.Jessica was in charge of marketing at a Boston investment bank. This bank thought it understood startups, but over the next year, as she met friends of mine from the startup world, she was surprised how different reality was. And how colorful their stories were. So she decided to compile a book of interviews with startup founders.', <EventPayload.TEMPLATE: 'template'>: <llama_index.prompts.base.Prompt object at 0x000001C164438C40>}, time='07/30/2023, 00:56:25.758377', id_='ea63bb8e-c733-4e10-bb71-69b98f6bd597')
dict_keys([<EventPayload.RESPONSE: 'response'>, <EventPayload.PROMPT: 'formatted_prompt'>, 'formatted_prompt_tokens_count', 'prediction_tokens_count', 'total_tokens_used'])
Growing up, the author worked on writing and programming. They wrote short stories and also tried writing programs on an IBM 1401 computer. They later transitioned to working with microcomputers.
Code language: Python (python)Bonus Tip 💡
Llama Debug Handler not only contains information about the current state of LLM, Infact there’s a lot more that you can do with it. For example, You can debug the following other parts the same way we did for LLM one.
- CBEventType.LLM
- CBEventType.EMBEDDING
- CBEventType.CHUNKING
- CBEventType.NODE_PARSING
- CBEventType.RETRIEVE
- CBEventType.SYNTHESIZE
- CBEventType.TREE
- CBEventType.QUERY
Happy coding 🦙! And you can checkout exciting things happening at LlamaIndex


