
Parsers are the backbone of retrieval augmented generation (RAG) apps. Parsers extract information from user-given documents and make it available to be fed into RAG apps. A variety of parsers are available for all formats of files and many are being developed and enhanced regularly.
In this article, we’ll take a closer look at an interesting parser LlamaParse that I discovered accidentally while exploring LlamaIndex repositories 😄.
LlamaParse as mentioned in the official repo is an API created by LlamaIndex to efficiently parse and represent files for effective retrieval and context augmentation using LlamaIndex frameworks.
For any RAG app, performance is directly proportional to how good the parsers are in extracting the pieces of information present in the files. The better the extraction, the better the augmentation. LlamaParse will take care of your PDF parsing needs so that you only have to worry about your RAG app.
LlamaParse provides the following features:
- Supports async batching which enables you to pass multiple PDF files in a go!
- Text and Markdown-based extraction, Markdown-based extraction can help you in parsing documents that contain tables.
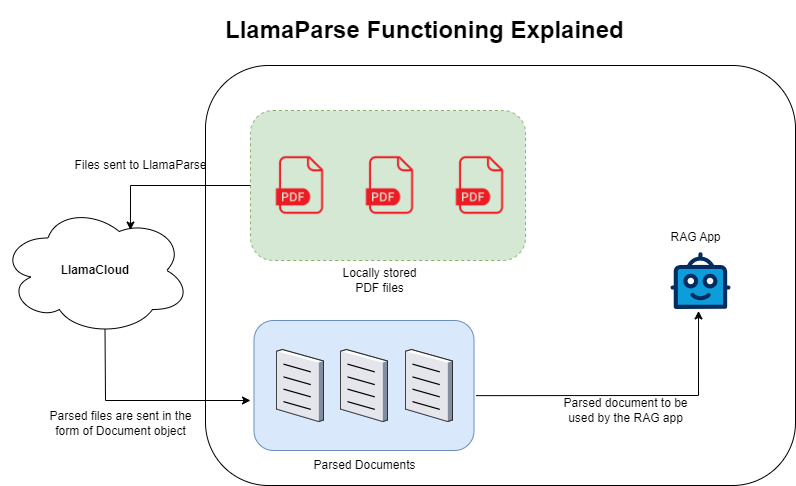
Setup
To use LlamaParse, You’ll require the following items in your bag:
- API key by registering at LlamaCloud
- llama-parse python library installed with
pip install llama-parse
Once you fulfill both requirements, you are good to go!
LlamaIndex is very popular for its “5 lines of code” starter template and the same they have done with LlamaParse too. See the example below.
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
parser = LlamaParse(
api_key="llx-...", # can also be set in your env as LLAMA_CLOUD_API_KEY
result_type="markdown", # "markdown" and "text" are available
num_workers=4, # if multiple files passed, split in `num_workers` API calls
verbose=True
)
# sync
documents = parser.load_data("./my_file.pdf")
# sync batch
documents = parser.load_data(["./my_file1.pdf", "./my_file2.pdf"])
# async
documents = await parser.aload_data("./my_file.pdf")
# async batch
documents = await parser.aload_data(["./my_file1.pdf", "./my_file2.pdf"])
# Integrate this parser with SimpleDirectoryReader
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader("./data", file_extractor=file_extractor).load_data()
Code language: Python (python)Parser will return data in the form of Document object which you can use to create Index.
Let’s do a live example testing with LlamaParse!
Live Experiment with LlamaParse
Using CRAG paper to demo the parsing capabilities of LlamaParse.
- Create a
.pyfile and add the following code.
from llama_parse import LlamaParse
import os
os.environ["LLAMA_CLOUD_API_KEY"] = "llx-..." # ADD YOUR LLMParse API key here
documents = LlamaParse(result_type="markdown").load_data("DOWNLOADED_CRAG_FILE_PATH")
print(documents[0].text[0:2000])
Code language: Python (python)- Run the py file with from any terminal:
python parser.pyand you’ll get output like this in the terminal:
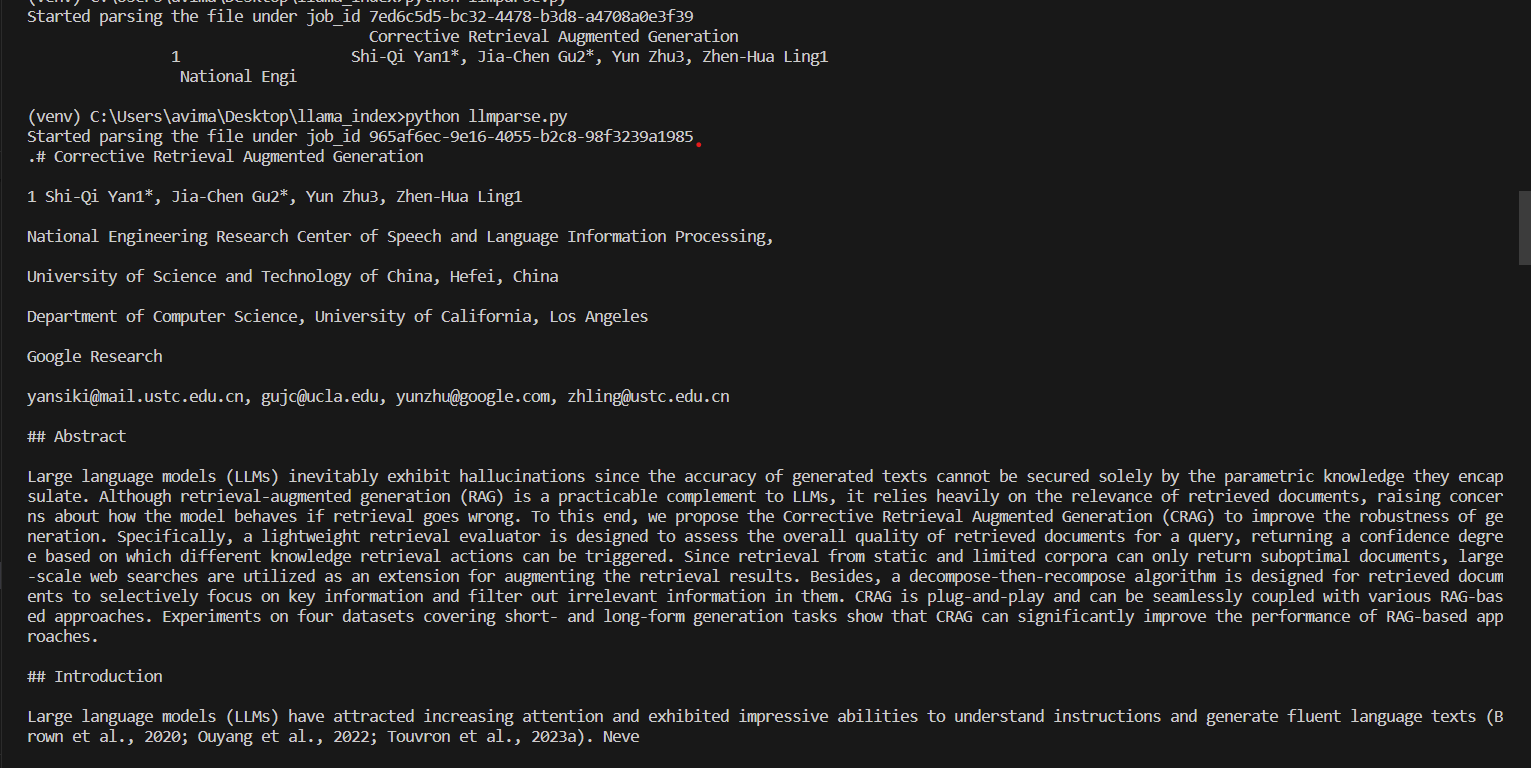
See how the printed data has heading and everything preserved. This will help in augmenting better responses!
Let’s combine LlamaParse and LlamaIndex together 🦙
Add the following lines of code in your current code to integrate LlamaParse into LlamaIndex and see for yourself how easy it is to combine these two. Updated code will look like this:
from llama_parse import LlamaParse
from llama_index.core import VectorStoreIndex
import os
os.environ["LLAMA_CLOUD_API_KEY"] = "llx-..." # ADD YOUR LLMParse API key here
os.environ["OPENAI_API_KEY"] = "OPEN_AI_KEY"
documents = LlamaParse(result_type="markdown").load_data("C:\\Users\\avima\\Pictures\\crag.pdf")
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
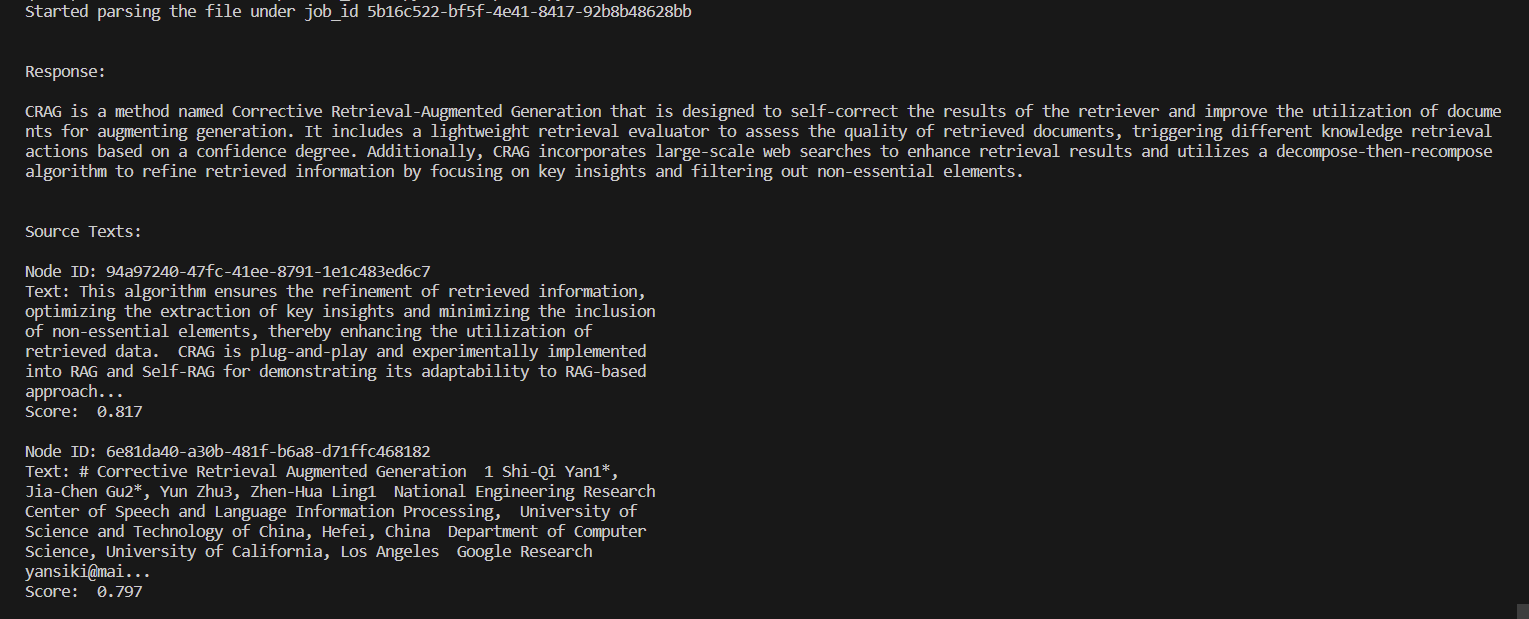
response = query_engine.query("What is CRAG")
print("\n\nResponse:\n")
print(response) # To check the repsonse
print("\n\nSource Texts:\n")
for source in response.source_nodes: # To verify if correct nodes have been picked or not
print(source)
Code language: Python (python)Run the code again and check the terminal for output, it should be something like this:
Conclusion
Parsing is the first step in improving the quality of your RAG app. It helps to make the LLM understand your data in a much better and efficient way.
Currently LlamaParse is supporting PDF format only, but more formats will be supported soon!
If you want to learn more, checkout to the repo: LlamaParse.
Blog reviewed by Logan Markewich from LlamaIndex team.
You can connect with on Twitter and Github and do checkout PythonWarriors


